-
 Blog
Blog
-
Preventing Inconsistency Bugs
Every software system has been built by copy & paste at least to some degree. Some of this redundancy is caused by technical limitations in the languages and tools. Some is caused by time pressure, where duplicating and modifying an existing piece of code is faster than developing suitable abstractions. Some is also caused by the laziness of the developers or missing awareness of possible long-term consequences. While these duplications often work fine when they are created, they typically cause additional maintenance overhead during software evolution, as duplicates have to be changed consistently. But the real risk of these duplications is in inconsistent changes, as this frequently leads to actual bugs in the system.
How serious is this problem?
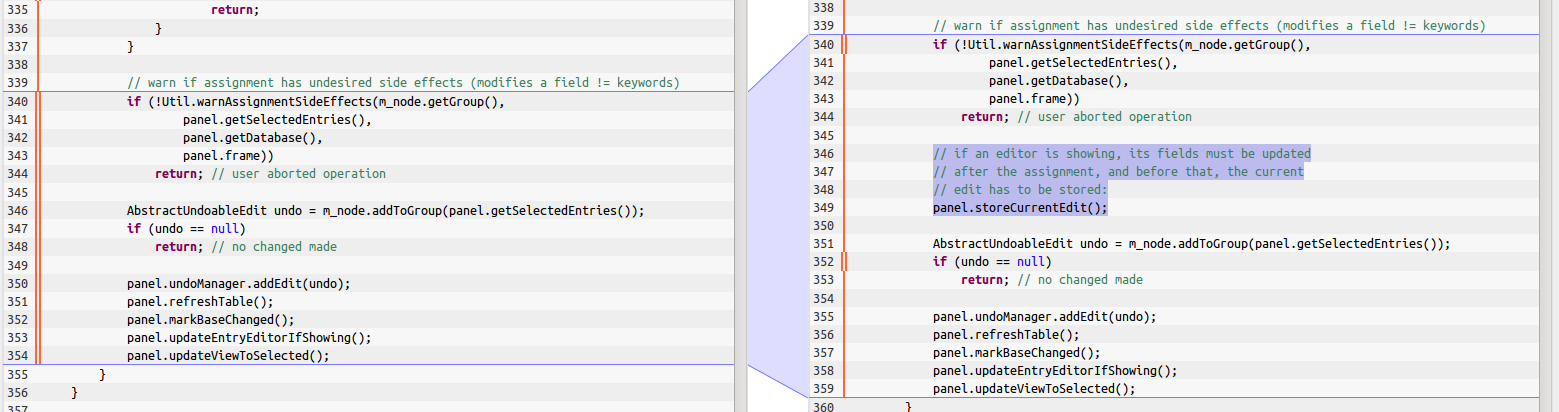
Duplicated source code created via copy & paste (also called code clones) is something we encounter in every software system to some degree (if you want an introduction to code cloning and clone detection, read my introductory posts here and here). The amount of cloning, also known as clone coverage, ranges between few (3 to 5) up to 30 or 40%, depending on the system and the kind of measurement used. There are also outliers with more than 80% of cloning, but on average, a project that does not employ any counter measures (such as continuous quality control) can be expected to have at least 15% of clone coverage. An example of such a clone is shown below.
One of our studies revealed that about half of inconsistent changes, where the developer was not aware of the existing duplicate, lead to a bug in the system, ranging from inconsistent logging to actual data loss. At the same time, the study found that without additional tools, about one third of inconsistent clone changes are performed unintentionally. In these cases, the inconsistent change was not an educated decision of the developer, but the developer was not even aware of the duplication.
Put together, we can expect about one sixth of all changes in clones code to cause bugs in the software (or prevent duplicated bugs from being fixed in all places). Assuming 15% clone coverage and an equal distribution of changes across the system (which might be an oversimplification), we can assume that more than 2% of all changes to the system lead to these inconsistency bugs. While this number seems small, just multiply it with the number of developers on your team and the amount of code touched by each developer every week and you get an idea of the risk of cloning.
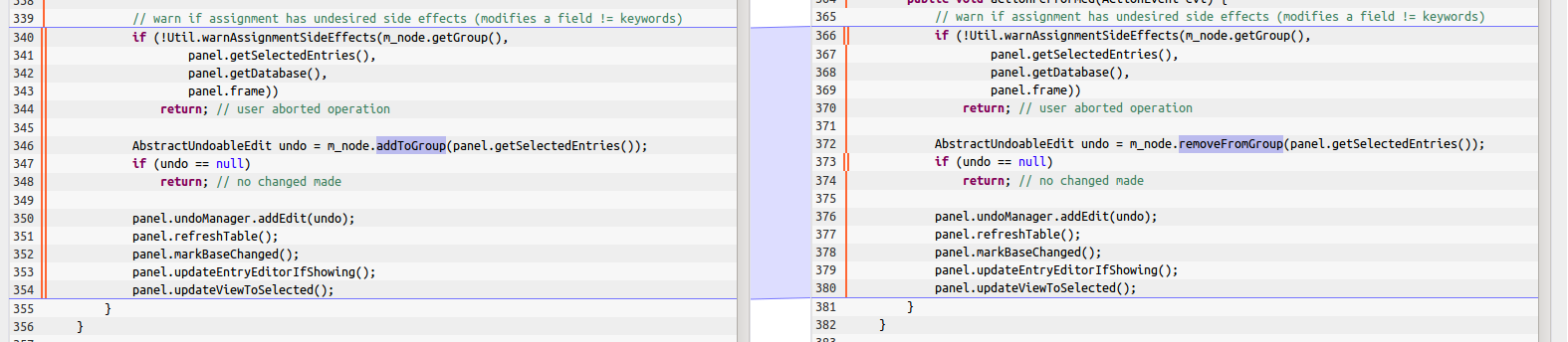
This also matches our experience, as we frequenty encounter cloned code, where comments hint at two separate change requests for a bug fix. There, a bug was found and fixed in one part of the code, but the propagation of the fix (the removal of the inconsistency) was performed later when the bug was also found at the other location. For the clone example shown before, there was a change (shown below) for only one of the locations, which looks like a consistent application to all copies would be required.
Preventing inconsistent modification
One possible reaction to the threat from inconsistent clone changes is to get rid of as many clones as possible. While this has other benefits, such as potentially reduced maintenance and testing costs, especially for grown code bases, this is nothing that can be performed in short time and is also not recommended.
A better solution is to educate developers and provide suitable tools that provide information about duplicated code to the developers as seamlessly as possible. While there are many tools for finding code clones, the developers can usually not be burdened with the execution of yet another tool. Similarly, checking a separate dashboard before every code change is not really a productivity boost. From our experience, the information has to be present in the code editor of the developer all the time. Only then, they might notice the clone and perform consistent fixes or even refactor the clone. This is essentially what our own tools do and with this we had a huge impact on the quality of our customers’ code bases.
Still, developers can miss clones, either due to time pressure or because the current task is too complex to allow any thought about quality issues. For these cases, it would be good to be notified of any inconsistent changes, so the developer (or a reviewer) can check these cases separately. Performing this kind of analysis in the nightly build is hard, as usually too many changes are accumulated over the day to get reliable results. Other approaches perform a full repository analysis that can take weeks to complete. Surely nothing you want to do regularly. Incidentially, our own analysis tool Teamscale uses incremental analysis to inspect every single commit in real-time. With only a minor modification, we now check every lost clone in each commit, for whether the cause might be an inconsistent modification. If so, the commit is flagged in the web UI and the developer (plus any other group you configure) gets informed by email. This way, inconsistent changes never get lost. The example given in the pictures was also found by Teamscale. The corresponding alert (shown below) indicates that this commit actually was a bug fix, but the developer seemed no to be aware that the same code (including the bug) was used elsewhere.

Try for yourself
I would be happy to read your thoughts in the comments. Also if you want to try our alerts for inconsistent clone changes yourself, just get in touch with me. The feature will also be part of the upcoming 1.5 release of Teamscale, planned for the end of this month. Just register for our newsletter to automatically get informed about the release.
