-
 Blog
Blog
-
Practical Guide to Code Clones (Part 1)
One well known principle in software engineering states don’t repeat yourself, also known as the DRY principle. A very obvious violation of DRY is the application of copy/paste to create duplicates of large portions of source code within the same code base. These duplicate pieces of code, also known as code clones, have been subject to lots of research in the last two decades. In this two-part post I want to summarize those parts of the current knowledge that I find most relevant to the practitioner, especially the impact of clones on software development and how to deal with them in terms of tools and processes.
Scientific disclaimer
Most of what I write here is not new, but scattered over many publications. If you want to check the primary sources, you can find a great overview in Robert Tairas' collection of Code Clones Literature. The best starting points are probably the well known surveys by Koschke and Roy/Cordy. I will also try to point you to research papers for further reading where applicable.
What is a clone?
A clone is a fragment of source code that appears at least twice in a system. Typically, we also allow code snippets that are not exactly the same, but have been modified slightly, for example different formatting, variations in comments, renaming of variables, and so on. Additionally, we require a certain minimal length to exclude very short fragments that are similar only because of certain common patterns (e.g., loop constructs). Often used values are 7 or 10 statements. You can see an example for a clone from the Jenkins source code in the following image (click for full size). The highlighted differences in the clone include different comments, variable renaming, fully qualified access of a field, and the usage of a method instead of a field in one place.
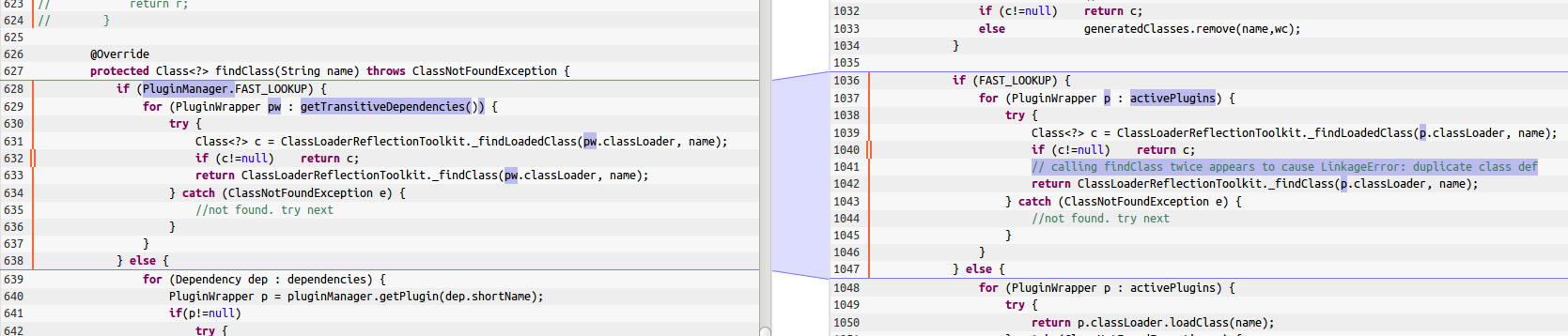
Probably, it would be possible to extract a common method for both of these fragments. But even if this is not possible, it is still very likely that any changes to one of the two pieces of code should also be applied to the other one. So the developers should at least be aware of this duplication.
The definition of a clone used here is purely syntactical, and thus only captures code created via copy/paste/modify. Code that solves the same problem but looks completely different can not be found in general.
Type-X Clones
Scientific literature often differentiates between different types of clones:
- Type 1: Exact copy, only differences in white space and comments.
- Type 2: Same as type 1, but also variable renaming.
- Type 3: Same as type 2, but also changing or adding few statements.
- Type 4: Semantically identical, but not necessarily same syntax.
Copy/paste: Who would do that?
When discussing cloning with developers, there are typically two reactions. Either they are convinced that in their team nobody would do something as bad as copy/paste, or they are sure that theirs is the system with the most clones ever. The truth is typically somewhere in-between. One way to determine the amount of cloning, is the clone coverage.
Clone Coverage
Clone coverage is the fraction of statements that is part of at least one clone (as clones can overlap, a statement might be covered by multiple clones). For example, assume there is a system with exactly 5 files (all of same length) and two files are completely identical and there are no other clones besides this. Then the two files would be covered by the clones, the others would not, resulting in a clone coverage of 40% (2 out of 5). The higher the clone coverage, the more copy/paste programming is going on.
A nice interpretation of the clone coverage is as follows. Assume that you pick a single statement of your code base at random. The clone coverage then is the probability that the statement is contained in a clone and so, when changing the statement, you might have to change this statement elsewhere to remain consistent.
Obviously, clone coverage strongly depends on the amount of clones found, and hence on the clone detection tool and parameters used. Thus, it is not a good idea to compare clone coverage values between systems, unless you used the same tool and configuration for both.
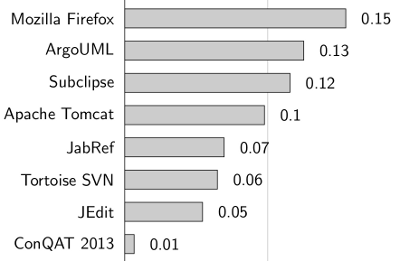
Using clone coverage, we can capture the extent of cloning in a single system. Typical values using our own detector are in the range between 5% and 15% (with minimal clone length of 10 statements), although we have seen systems with 50% clone coverage and more. Some clone coverage values for Open Source systems are shown in the following chart. Note that values below 5% clone coverage are very rare. As you can see from the low values for our own tool ConQAT, we eat our own dog food.
Cloning considered harmful?
Using suitable tools, we can easily determine that clones can be found in nearly every non-trivial piece of software. Our measurements of clone coverage also suggest that most systems have not only a few clones, but lots of them. But are clones actually a problem?
Cloning considered harmful considered harmful
In science, answers are never simple. Kapser/Godfrey, for example, state that cloning actually helps to create new features quickly and reduces the risk of changing existing functionality. Krinke finds cloned code to be changed less frequently than non-cloned code; while he concludes that this indicates that maintenance of this code then is cheaper, it could also indicate that developers try to avoid changing cloned code if possible. Rahman/Bird/Devanbu find cloned code to be less error-prone than non-cloned code. Our own study, however, found that for cases where a developer changed one part of a clone without being aware of the duplicate, every second of these inconsistent changes caused a bug in the system. There are many more studies, but the main issue is that they all have a different idea, what is meant by the term problem.
In practice, the answer is very simple: It depends. When building a prototype, which will be thrown away soon, you should actually use lots of copy/paste, as this will help you to implement features faster. The same holds, if your employer pays you by lines of code. When your focus is long-term maintenance of your code-base, clones will be a problem if you are not aware of them. Changing cloned code in a non-consistent way often leads to bugs. But to prevent this, you might not have to eliminate all clones. It might be sufficient to have a tool that keeps you aware of clones in code you are changing.
Personally, I find it tiresome to work with code in many clones. Having lots of déjà vu moments during development, because the code looks the same everywhere, does not fit with my image of being a software professional. While surely there are cases, where elimination of a clone is too complicated, I try to keep my code as clone-free as possible. What about you? I would be happy to hear about your opinion in the comments.
What is next?
This concludes the first part of our mini series. I hope you got an idea what code clones are about and whether they are interesting for your own development work. In the next part we show you, which tools you can use for detecting clones in your code base and how to deal with clones in the long term.
