-
 Blog
Blog
-
Practical Guide to Code Clones (Part 2)
Lesen Sie hier, wie es dazu kam, oder sehen Sie Aufzeichnung des CQSE Software Intelligence Talk am 10. Mai (10:30-12:00 Uhr) von Li Yang Wu (dmTECH) und Dr. Nils Göde (Head of CQSE Softwareaudit)!
In the previous part we introduced the notion of code clones and discussed, whether and under which circumstances cloning in your code base can be a problem for development and maintenance. In this post, I will introduce ways and tools to deal with code clones in your code base. After reading this, you should be able to select and apply a detection tool to inspect the clones in your own code base.
Disclaimer
I was involved in the development of multiple generations of the clone detection engines and clone management support of our tools ConQAT and Teamscale. Although I try to present a neutral view in this post, the examples are taken from these tools I know very well and I might be biased to some degree.
Where are those clones?
Finding a code clone in a single file manually is very tedious; finding all clones in millions of lines of code this way is impossible. Fortunately, there are tools that can help with the detection of these clones.
Detection approaches
Over the last years, lots of different approaches for clone detection have been proposed. One common way to categorize these approaches is the code representation used. The most common ones are
- Line-based: The elements that are compared are lines of code. This has the benefit of being the only approach that is independent of the programming language. The drawback is that code is typically not recognized as a clone, as soon as the formatting is changed (different line breaks) or a variable is renamed.
- Token-based: The elements that are compared are single tokens, such as identifiers or operators. This approach allows for differences in formatting, but some differences (such as qualification with this) can be hard to compensate.
- Statement-based: This works on single statements of the code. Using this approach, the compensation of intra-statement changes can be easier.
- AST-based: Some algorithms work on the abstract syntax tree (AST) created by a parser. They usually compare entire sub-trees and thus can lead to clone findings that are better aligned to the structure of the code.
- Method-based: Some approaches limit the search to entire methods. As they are not capable of finding clones that only affect a part of a method, they are often of limited practical usefulness.
- Graph-based: Some approaches work on a graph representation of the code (e.g., a program dependency graph (PDG)). While they can find some interesting clones, these approaches usually are not fast enough for systems with more than 20,000 lines of code.
One core question when dealing with clone detection tools is that of precision (are all clones reported meaningful clones) and recall (do we really find all clones or are some of them missed). Unfortunately, the question is not an easy one, as the assessment of a potential clone often depends on the use-case and developer at hand. Take for example the following two code snippets. According to the definition, these are clearly (type-2) clones as they have the same syntactic structure. But most developers would agree that this is not a very helpful clone as both fragments are completely unrelated. At the same time, we would like to find this, if only one or two identifiers were different.
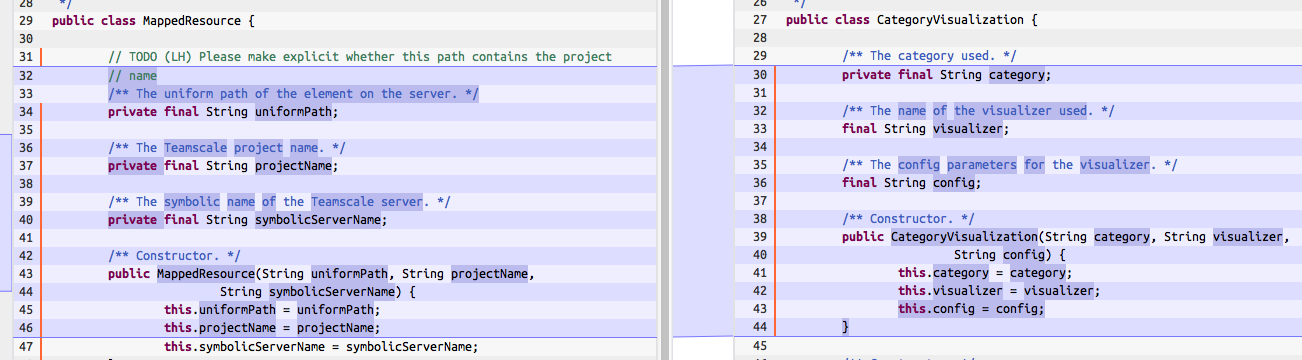
To deal with such clones, most tools implement multiple heuristics that can filter clones based on additional criteria. As a consequence, it is really hard to compare clone detection tools based on technical facts alone (detection approach, clone types found, etc.). If you want to compare tools, you have to compare their results on a code base you are familiar with.
Living with clones
I have yet to see a system without a single clone. And usually it is not feasible to remove all of them at once (we also would not recommend this). So you have to find ways to deal with them during development and maintenance of your system. This is often referred to as clone management.
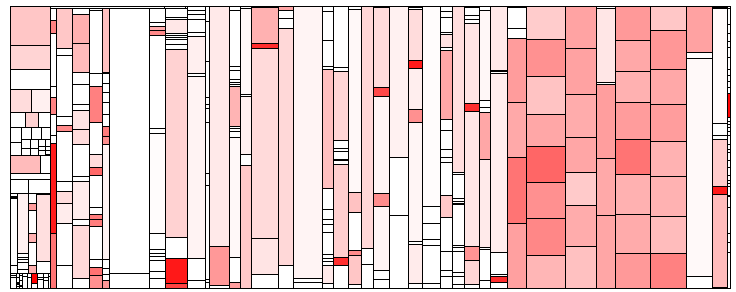
The first step is to be aware of the clones in your system. This obviously includes the detection of the clones, but you also need ways to visualize the amount and distribution of the clones and inspect individual clones. The most aggregated view on the clone of a system are clone metrics, including the number of clones and especially the clone coverage (see part 1 for an explanation). One way to visualize the distribution of clones in your system and find potential hot-spots are treemaps. In a treemap, each rectangle corresponds to a file and the area of the rectangle is proportional to the size of the file. Rectangles are organized in a way that files in the same directory are next to each other. The color then displays the clone coverage of the file, i.e., the amount of cloning. The example below shows an example for the system doxygen. The more red a rectangle is, the more lines in the file are covered by clones. There seems to be a tendency of more clones in the files at the right. Usually, these treemaps are interactive and would allow to find out which directory or component these files correspond to.
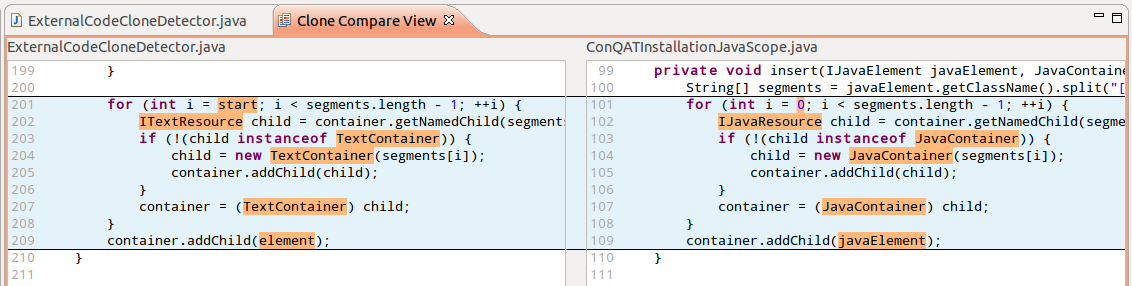
For inspection, I found the easiest and most intuitive way the clone diff or clone compare, which shows both code snippets side by side, including context and highlighting differences.
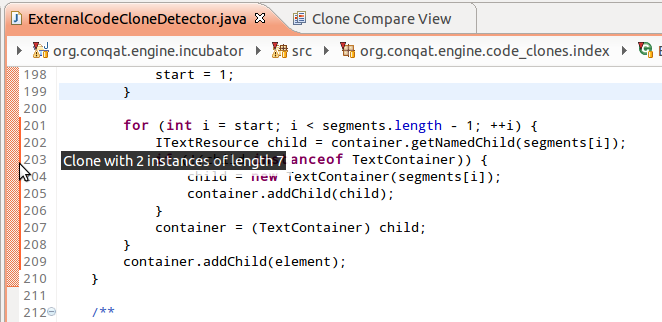
Additionally, for development, it is important to get the information not only in some tool reports, but right in the IDE. Our tools, for example, highlight clones (and other quality issues) using a red bar at the left side of the code editor. This way, a developer is aware of potential problems during coding and can directly jump to the clone compare view without switching tools.
But management is not limited to staying aware of the clones. You also want to understand the impact of development on the amount of cloning. Besides the obvious trends of selected clone metrics, you typically want to be informed of any new clones that are created, so you can react while they are still fresh. This distinction between new and old clones is often referred to as clone tracking.
Actually, there are also some tools that promise to automate clone removal. So far, I have not seen a tool that really convinced me. Part of the problem is that the logical unit a developer would extract is typically not exactly the clone. Additionally, the code does not really get more readable, if the newly introduced methods are called m1 to m42, as some tools do. For sure, there are ways to simplify removal of clones, but I do not believe in solutions that work without any human interaction.
Show me those clones
After so much theory, you probably want to get your hands dirty and check your own code base. There are lots of research prototypes, but most are not easy to obtain and even harder to use. There are tools that focus on clone detection alone, such as PMD’s copy-paste-detector or the commercial tools CloneDR and SolidSDD. All of these tools, however, are pure detectors with only limited clone management support, although SolidSDD has some pretty visualizations.
One good starting point is our clone detection tutorial for Java and C#. It uses our Open Source analysis toolkit ConQAT and implements variouos detection algorithms. If you want to see full-blown clone management in action, I recommend to check out the live instance of our real-time software quality analysis and management suite Teamscale.
Configuration
As explained before, most clone detection tools support many different heuristics that can also be fine-tuned to specific use-cases. While the default settings should provide a good starting point, specific applications can benefit from fine-tuning. Additionally, you should always configure your tool to not analyze any generated code. Generated code looks very similar as the generator uses the same template over and over again, so you will find many clones there. However, as the generated code is never changed manually (or at least should be), the redundancy in this code does not matter at all and will only distract you from the relevant clones.
The journey just began…
I hope you got a good overview about how to deal with code clones in your code. The area of clone detection research is still very active, so we can expect that more practically useful applications will evolve over time. One example is the application to other artifacts besides source code, such as dataflow models and requirements specifications.
If you have any further questions regarding code clones and tools, feel free to contact me or post a comment.
