-
 Blog
Blog
-
To Blacklist or Not to Blacklist
Analysis tools for your source code, like Teamscale and others, produce a list of findings—or issues—identified in your code. When you go over the list of findings, you will probably encounter some individual findings you will not fully agree with. These issues might be not valid, not a problem or not worth to fix for you. For these cases, professional quality analysis tools offer blacklisting features. Blacklisting allows you to hide individual findings. The question »What should be put on the blacklist?« will be answered quite differently, depending who you ask. Developers may tend to »everything I cannot fix should be on the blacklist«. A QA manager might answer something like »only false positives may be put on the blacklist«.
Blacklist Everything that Cannot be Fixed
In general, the first position is far too tolerant: The reason why something cannot be fixed is the key point. There are two basic reasons: Either a finding could not be fixed since there is no suitable technical solution or there is no time (or no budget) to fix it. The first are natural candidates for the blacklist (and these are actually false positives).
But what about findings, where fixing them is just too much effort? In general, I would recommend to not blacklist findings solely because the effort to fix is too high. Even if the effort is too high now, it might be reasonable to fix the finding when the code is modified the next time. Instead of blacklisting, filter findings with respect to a reference date, the baseline, is the better approach. With the baseline you can define earlier introduced findings as »old findings«. Having the findings filtered w.r.t the baseline, you can focus on the new findings. This avoids that you have to go over many findings again and again, which you already know (but which won’t be fixed now).
There might be also findings, which result from (bad) global design decisions and hence cannot be fixed without broader restructuring of the code base. In my view, these are very close to no suitable solution—with respect to the current design. These might be put on the blacklist—but probably a ticket should be opened to rework the code design.
Blacklist Only False Positives
Is the second position, to blacklist only false positives, the better approach? Before coming to this, we must first clarify what a false positive is. These are findings, which are somehow invalid. However, there are different rationales to consider a finding as not valid: Because it was wrongly detected, because there is no solution for it or because it is not an actual problem.
A wrongly detected finding would be for example a code clone, which is no actual duplicate, or a method were lines, statements etc. are counted incorrectly. Of course, these qualify for the blacklist but the better solution is to fix the analysis engine or analysis configuration. The same counts for findings where no solution exists—but in some cases it is not possible to detect that there is no solution for a finding, e.g. when some framework technology (which is not part of the analysis) requires for example a variable, which is otherwise unused, and hence reported as finding.
The third interpretation of false positive, everything that is not a problem is a false positive, is in contrast very vague. Different people might have a quite different opinion on what is a problem and what is not. Thus, I prefer such findings not to regard as false positives because it is a too subjective judgement. Remember that the analysis profile should reflect what has to be considered as problem. For example: You can argue a lot about the optimal threshold for the length of a method. Once you agreed on a certain threshold, it should be the aim to have as many methods as possible within this threshold, even if the individual improvement seems to be only marginal.
More Practicable Blacklisting Strategy
However, blacklisting actual false positives (analysis errors and findings without solution) only is a too strict approach in my view. Why? Because improving the quality of the source code is the overall goal. Thus fixing a finding should contribute to that goal. Let me state an example: Assume an otherwise simple-structured method which only slightly violates the method length threshold. There is no error in the analysis and most probably, you could somehow split the method to fix the finding. However, there is no improvement if you split someMethod() into someMethodPart1() and someMethodPart2() rather the contrary. If there is no logical split possible, it might be better to leave the method as it is. It is a candidate for the blacklist. Note: the amount of findings for which no fix exists which is not at least a little improvement is most likely only a (small) subset of all findings that are regarded as »no problem«.
Summary
As I described before, neither of the two strategies »blacklist everything that cannot be fixed« or »blacklist only false positives« is very precise to identify the findings which are candidates for the blacklist. More practicable in my opinion are the following rationales:
- Finding was incorrectly detected
- No solution possible
- No fix would improve quality
- Finding results from global design decision, requires broader re-design
Blacklisting in Teamscale

Finally some words on blacklisting in Teamscale: Of course, Teamscale offers the possibility to blacklist individual findings. The screenshot above shows the finidings detail page with the Blacklist button. Teamscale has some additional features to make blacklisting findings easy to use and easy to follow:
- It is required to enter a rationale when somebody blacklist—no finding must be blacklisted without reason. Further Teamscale logs who blacklisted and when.
- With the Teamscale plug-in for Eclipse blacklistling is possible directly in the IDE, not only from the web interface.
- The list of blacklisted findings is as comfortable to use as the list of non-blacklisted findings—thus reviewing the blacklist is easy.
- Even if the blacklist hides the individual finding, the metrics (for example the clone coverage) are immune against blacklisting. Hence, the metric values still reflect the real overall situation of your code base.—If there are 50% duplicated it will be a maintainability problem, even if the findings are on the blacklist.
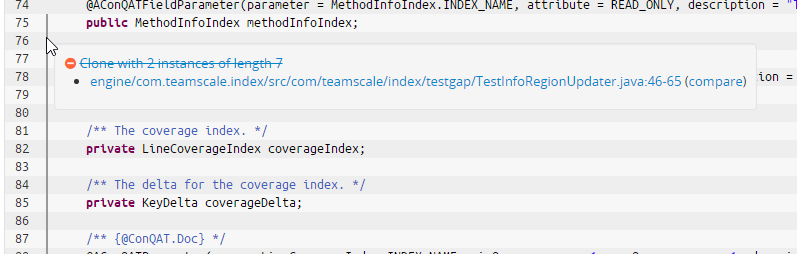
- In the code perspective, teamscale indicates blacklisted findings with a discrete gray marker (see screenshot below). Thus you can have a quick look, what is blacklisted here.
- To cope with legacy findings Teamscale’s baseline and delta features are much more powerful, as mentioned before. Blacklisting is not the right approach to to filter a large number of old findings.
