-
 Blog
Blog
-
Is Your Build Ready for Continuous Deployment? A ...
Most of the posts in this blog focus on measuring and improving the quality of software systems. When talking about software quality most of us think about the quality of its source code. However, with the recent trend to continuously deliver new releases the quality of build scripts and thus maintenance costs are becoming increasingly important. From auditing the build systems of our customers we know that coping with clones in build scripts significantly increases maintenance costs and hampers implementation of new build features. This post summarizes how we compared 3,872 systems to interpret cloning in build scripts and examine how it can be avoided.
Build scripts are a crucial part for delivering a software product in a consistent way. These scripts can reach a high degree of complexity and are responsible for tasks that go far beyond just building an application. These tasks can roughly be categorized into 5 phases:
- Configuration: Select tools, configure build technology, resolve dependencies
- Construction: Transform source code into deliverable
- Testing: Automatic execution of regression tests
- Packaging: Bundle deliverables (application, data, documentation, …) for end users
- Deployment: Automatic staging to testing or production environments
Of course not all of these tasks have to be implemented by hand, since the used build technology (Ant, Maven, MSBuild to name just a few) provides convenient ways to compile, test, or resolve dependencies. But often these technology functions have to be configured or enhanced.
The recent adoption of continuous delivery comes along with more frequent change requests to the build system. Hence, the quality of build scripts and the time spent to implement changes become increasingly important. We saw, however, that applications that are orchestrated from multiple components or pools of applications that are built in a similar manner, have a tendency to duplicate build logic for each component or application. Thus, modifications for simple change requests need to be applied on multiple locations and increase the efforts to maintain the build scripts—needless to say that flaws may be introduced if some locations are forgotten to alter.
Creating a benchmark
In contrast to cloning in source code there is no concrete understanding of cloning in build scripts. The questions that come into our mind are:
- How much cloning is typical?
- What is actually cloned?
- Is cloning a problem of chosen technology or a general problem?
- Can cloning be avoided?
To answer these questions we teamed up with Shane McIntosh from Queen’s University who is a very active member of the research community regarding build systems and release engineering. He also has access to a large corpus of Java and C/C++ open-source software systems (including build scripts) that originate from GitHub, SourceForge, Apache and Savannah (GNU). With our quality analysis tool ConQAT we analyzed cloning within 3,872 systems with build scripts written in GNU Autotools, CMake, Ant and Maven.
How much cloning is typical for my build technology?
Before taking a look at the results let’s quickly summarize how we configured the ConQAT clone analysis:
- Clone detection is line-based
- Minimum clone length of 5 lines
- Leading and trailing white space is ignored
- Empty lines are ignored
- Lines containing comments are ignored
- Closing XML tags are ignored
To summarize these technical details, a clone must span at least 5 lines that are neither empty nor contain comments or closing XML tags. But I don’t want to bore you, here are the results:
| Ant | Autotools | CMake | Maven | |
|---|---|---|---|---|
| Median Clone Coverage | 29.8% | 0% | 2.0% | 49.3% |
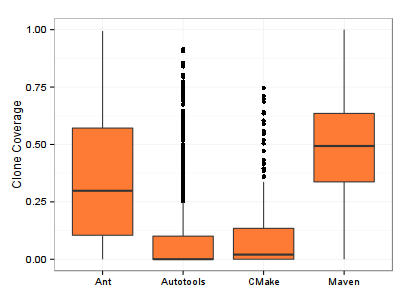
The median clone coverage from the benchmark shows that cloning varies between different build technologies. For Java build scripts, one can expect a clone coverage around 30% for Ant and around 50% for Maven. The C/C++ build scripts from our benchmark have a much lower median clone coverage which is almost zero for Autotools and around 2% for CMake. This yields the following observations:
- Build scripts for C/C++ (Autotools, CMake) have a significant lower clone coverage than the ones for Java (Ant, Maven)
- Build scripts for newer build technologies CMake and Maven are more prone to cloning than the older Autotools and Ant
What information is actually cloned?
To answer this question Shane and I manually inspected 1,491 randomly chosen clones (for the statistic experts, this gave us a 95% confidence level, and that was a bunch of work). The following table summarizes how the clones are associated to the previously explained build phases. In case you are still excitedly following, summing up the numbers will go beyond 100% because several clones had to be associated with multiple phases.
| Ant | Autotools | CMake | Maven | |
|---|---|---|---|---|
| Configuration | 32% | 22% | 40% | 79% |
| Construction | 64% | 56% | 66% | 17% |
| Testing | 12% | 13% | 11% | 4% |
| Packaging | 25% | 21% | 2% | 21% |
| Deployment | 11% | 9% | 7% | 1% |
For Java build scripts cloning shifts from construction in Ant to configuration in Maven
I find this result very interesting, as it shows how the build technologies have evolved over time: In Ant build scripts, one has to call the Java compiler or JUnit by hand and must specify the class path. Most Maven build scripts in contrast use already available build modules that handle compilation, testing, and packaging out of the box and just leave the maintainer of the build script with configuration duties. If one follows standard Maven patterns for project layout one often can omit configuration at all.
Oh wait, haven’t you just told that Maven had the highest clone coverage out of all build technologies? True, but Maven also manages third party library dependencies for Java systems and we found that every second clone (54%) concerns the dependency lists of the project. Moreover, configuration is more stereotype than writing actual build logic and is thus more prone to cloning. Hence, systems that were composed of subsystems with similar dependencies and configuration showed a high clone coverage.
For C/C++ build scripts most cloning occurs in the construction phase
For C/C++, the more recent CMake build technology has more configuration clones then the older Autotools and thus follows the same trend we observed for Maven and Ant. However, for both Autotools and CMake most clones belong to the construction phase. This is also obvious as the compiling process for C/C++ is far more configurable than for Java and involves lots of compilation flags and file lists.
CMake shows almost no cloning in the packaging phase as it has built-in support for packaging (CPack). For Autotools, we saw some redundancy between lists of files needed for packaging.
How can cloning be avoided?
We observed that entire files were duplicated for systems with the highest clone coverage. In these cases, existing build scripts are copied to, e.g., rapidly develop new subsystems. On the other hand, systems with low clone coverage leveraged build technology mechanisms to abstract or include functionality and got rid of redundancy. Still, not every clone is resolvable with built-in functionality, so we came across some build scripts in the benchmark set that were (ab)using XML entity expansion to import common logic.
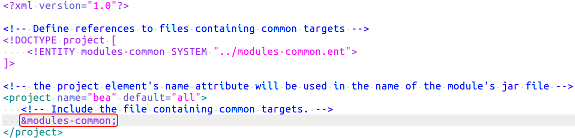
In general cloning seemed to be most relevant for systems that divide into several subsystems that are similarly built. In these cases we saw larger efforts to create a build framework that sits on top of the actual build technology and just has to be configured for each subproject. A good example for this is JBoss Buildmagic. Our own products Teamscale and ConQAT are built with such a build framework as well that bootstraps Ant build files for each subproject.
Summary
With the adoption of continuous deployment, build scripts are becoming increasingly important. However, build scripts suffer from similar problems as regular source code does. From our own experience one of these problems is cloning. For more recent build technologies (Maven, CMake) most of the cloning concerns configuring the used build technology. This is mainly due to the fact that common build steps like compilation, testing, or packaging are already provided by the build technology. Similar to programming languages, templating or inclusion mechanisms can be used to reduce redundancy by separating common logic from build scripts.
From our experience tidying up the build scripts and resolving redundancy is an achievable task, but you may need to work around limitations of the used build technology. Besides lowering maintenance efforts when altering the build logic, you will most likely gain a more uniform layout of subsystems of your application—they are built using the same rules and these have to be adhered. In the end this also helps developers switching between subsystems as they find a similar project layout.
We used the results of this study to propose and implement a solution for reducing redundancy in scripts from a 1.1 million LOC build system of one of our customers. But giving details of this big refactoring and its implications is a different story for a future blog post…
For further in-depth information and statistical details, I’d recommend reading the scientific article Collecting and Leveraging a Benchmark of Build System Clones to Aid in Quality Assessments we published together with Shane McIntosh, Audris Mockus, Bram Adams, Ahmed E. Hassan, Brigitte Haupt and Christian Wagner in the proceedings of the 36th International Conference on Software Engineering 2014.
