-
 Blog
Blog
-
Our Teamscale Production Setup
Parts of this post are outdated. Please refer to our official documentation for an up to date guide regarding setting up Teamscale with a reverse proxy like Nginx.
Over the years, we have set up Teamscale for many customers. During these times, we learned a lot about how to set it up, which other tools are useful and how to maintain a Teamscale instance over time. We worked with small as well as with large teams and infrastructure ranging from the PC under some guy’s desk to a multi-server installation in the cloud. Throughout all of these ventures, we found some best practices that I’d like to share with you.
These best practices serve several different goals:
- We want to be able to test new Teamscale releases before we roll them out to everyone, in order to make sure that the rollout will be smooth.
- We want to be able to experiment with different Teamscale configurations without affecting the people using Teamscale during their daily work.
- We don’t want to have unnecessary downtime during updates. Major version updates of Teamscale require a reanalysis, which can take some time for larger setups with lots of projects. We don’t want to have to tell people they can’t use Teamscale during that time.
- In bigger setups, we’ll have to integrate a lot of external data with Teamscale (build results, test results, test coverage, …). We want that to be as painless as possible.
In our experience, all of these goals can be reached with the following setup:
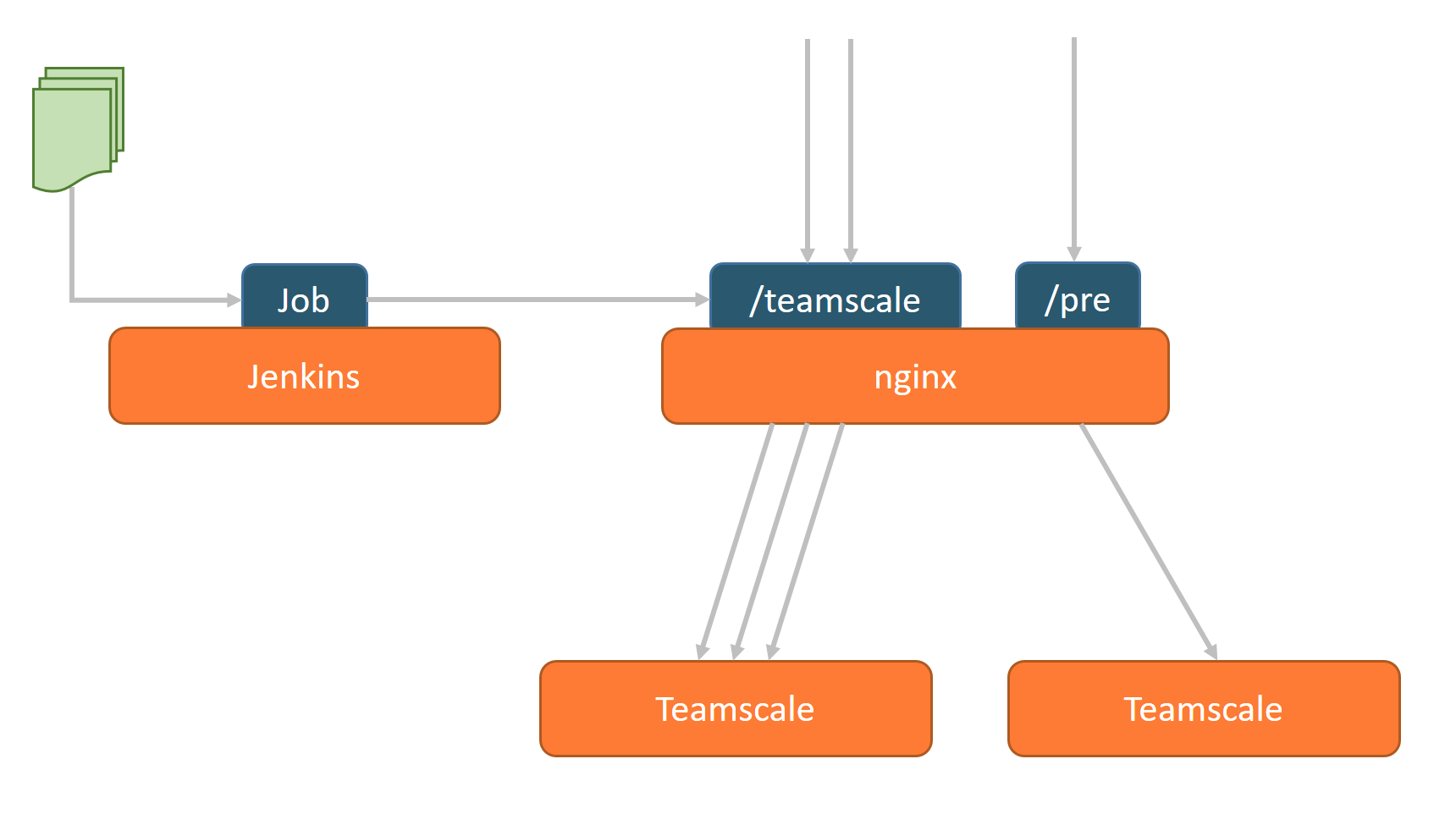
Let me explain the different parts here.
Shadow Instance
We run not one but two Teamscale instances: One that serves all current »production« requests (i.e. the one the teams actually work with) and one for testing purposes (e.g. testing major releases, experimental project configurations, experimental integration with new infrastructure, …). This allows us to keep the production instance stable and safe while we can go nuts with experiments on the »preview« or »shadow« instance.
Please note that all of the depicted services could also be Docker containers. We have had good experiences with a dockerized setup orchestracted by docker-compose so far.
Reverse Proxy
These two instances need to be available under different URLs, e.g. /teamscale for the production instance and /pre for the shadow instance. We recommend to use a reverse proxy to handle incoming requests for both endpoints and forward them to the two Teamscale instances. Our tool of choice for this is nginx. Here’s a sample config for nginx to proxy the requests:
http {
upstream ts-prod {
server localhost:8080;
}
upstream ts-pre {
server localhost:8081;
}
# default proxy settings
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# allow longer timeouts since some admin services can take longer to complete
proxy_connect_timeout 300;
proxy_send_timeout 300;
proxy_read_timeout 300;
send_timeout 300;
client_max_body_size 2000M; # allow big files to be up/downloaded, e.g. backup zips
server {
listen 80;
listen [::]:80; # IPv6
server_name example.com;
location /teamscale/ {
rewrite ^ $request_uri; # make sure the url encoding is left as is
rewrite ^/teamscale/(.*) /$1 break; # remove the prefix for the proxied instance
return 400; # second rewrite didn't match (e.g. //teamscale/), better bail out for security reasons
proxy_pass http://ts-prod$uri; # pass the correctly encoded and stripped url to the instance
proxy_redirect / /teamscale/; # add the prefix again for redirect responses from the instance
}
location /pre/ {
rewrite ^ $request_uri;
rewrite ^/pre/(.*) /$1 break;
return 400;
proxy_pass http://ts-pre$uri;
proxy_redirect / /pre/;
}
}
}
The big advantage of using a reverse proxy is that it allows us to switch between both Teamscale instances with next to no downtime. Simply edit the nginx config file, exchange the two servers and reload nginx without any downtime. Now the old shadow instance has become the production instance and vice versa.
The Switch
There’s more to making this switch, though. Teamscale analyzes not only the current state of your code but its entire history—commit by commit. This allows us to have very powerful tracking of findings, test gaps, etc. We can also give you very personalized feedback on your commits. This approach, however, requires that upon major version updates, the history is re-analyzed. Otherwise, analysis results would not be consistent across the entire history. Depending on the length of the history and the size of the project, this may take a while.
In our scenario, the shadow instance is performing this re-analysis, while developers and testers continue to work with the old release. During the time it took Teamscale to reanalyze all projects, users might have changed dashboards, their settings, issue queries, etc. Furthermore, external analysis results (coverage, build results, …) might have been uploaded to the old production instance. We don’t want to lose all these changes when we switch over to the new Teamscale version. So what we have to do before the switch is transfer this delta in Teamscale’s data over to the new production instance, but without reanalyzing all projects.
- Export a full backup of the old production instance
- Import this backup into the new production instance but check the import option called Skip project creation and only update external data.
The effect of this is that
- all global data in the new production instance is updated to match the old production instance (i.e. users, dashboards, account settings, …)
- external analysis results and settings of each project are updated to match the old production instance (e.g. issue queries, blacklists, …)
- the projects are not reanalyzed
After the backup was imported successfully, perform the switch of both instances in Nginx (you don’t have to wait for any further analysis work to complete). Thus, the users see almost no interruption in their normal usage of Teamscale and keep all their data.
One word of warning: please never use the abovementioned option Skip project creation and only update external data on your production Teamscale instance. Only ever use it on your shadow instance. This can cause data corruption if at the same time the backup is imported, external data is uploaded to Teamscale via the REST interface.
External Analysis Results
The last one of our goals was to provide transparent integration of Teamscale with sources of external analysis results (coverage, process metrics, …). This usually means running one or more recurring jobs that upload this data to Teamscale. There are many tools to schedule such recurring jobs (Windows Task Scheduler, cron, …) but we have made the best experiences with Jenkins. Using a build tool for this purpose has several advantages:
- you can trigger jobs based on a variety of conditions besides regular time based triggers: files being present on the file system, commits in a VCS, …
- it keeps and rotates logs for you, which is helpful when something goes wrong
- it lets you see at a glance when jobs fail
- you can trigger jobs directly from the UI
- you can temporarily disable jobs
When uploading such external analysis results, we recommend you send them via the nginx endpoint for the production instance. This way, when you switch between two instances as described above, the results are always guaranteed to be sent to the right Teamscale.
Next Steps
We are currently experimenting with a good default setup for monitoring Teamscale and Jenkins with Sensu. This tool allows us to be notified when something goes wrong (Teamscale is not running, Jenkins jobs fail, problems with the quality of external data, …). This lets us react faster to problems and thus keep Teamscale instances running more smoothly for the development teams. Stay tuned for more details about this in a future blog post!
