-
 Blog
Blog
-
Improving the Quality of Manual Tests
When you say »software test«, most people will immediately have a mental picture of automated unit tests, continuous integration, fancy mutation testing tools etc. But in reality a large portion of testing activities is still manual, i.e., someone clicking through the UI, entering values, hitting buttons and comparing on-screen results with an Excel sheet. Such tests are sometimes exploratory (i.e., the tester performs some random actions in the UI and reports any bugs he may or may not encounter on the way) and sometimes they are structured (i.e., someone writes a natural-language document with step-by-step instructions for the tester).
In our long-running research cooperation with TU München and our partner HEJF GbR, we have encountered large regression test suites (i.e., hundreds of test cases) in many different companies that were built this way. Usually some test management tool is used to store these test descriptions and monitor the execution progress. Such test suites evolve and grow over time and are reused with every new release of the software.
Quality is a big concern for these documents. As maintaining them is a long-time effort, they face many of the same challenges we encounter with source code: They are read, interpreted and edited by many different people with different backgrounds and they need to be modified frequently to reflect changes in the application. Additionally, unlike source code, the people writing the tests are often not the same as those reading and interpreting them.
How to Improve?
Realizing that quality is important is one thing. Actively improving that quality is another. First, you need transparency about the location of the problems, then you need effective ways to improve. Static analysis can help with the first part, as certain problems can be detected programmatically. Here are some examples:
Complex Test Cases
Maintenance costs are mostly driven by how much effort it is to make changes to the existing test cases. Complexity is a big factor here, since modifying a complex test case correctly requires a deep understanding of it.
Complexity in test cases can come from many sources. Test case writers may try to cover too many scenarios in one test case, resulting in lots of complicated branches, conditional steps in the execution, and overly long test cases. To identify unnecessary complexity, a static analysis can find conditions in the text. Long steps and sentences can also be highlighted. Tests that contain many of these problems are likely candidates for improvement:
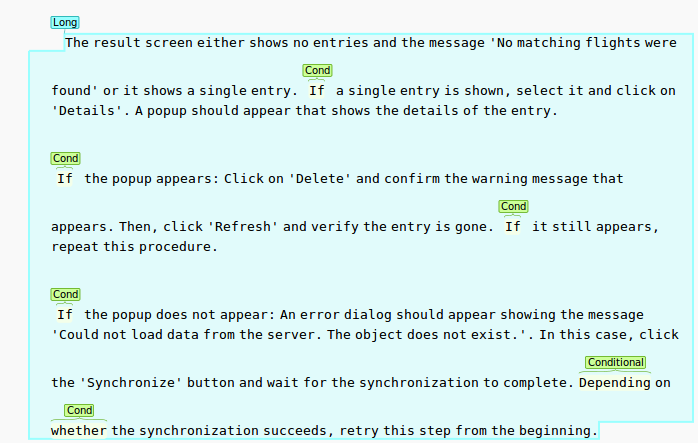
This image shows several examples of conditions in the text that can be hard to understand. They also make it hard for the tester to navigate the test description correctly as it is no longer a linear sequence of actions and checks, but instead contains branches and even loops. The excessive length of the step also means that the tester may have a hard time reporting where in the test case a problem occurred and needs to take extra care to not accidentally skip a line and miss some crucial information. If we refactor these test cases and, e.g., split them up into multiple ones or separate long passages into multiple steps, we will help the person who is executing that test case understand and execute it correctly.
Copy-and-Paste
Writing new tests by copying existing ones (so-called cloning or copy-and-paste) also has a huge impact on maintenance costs, since a modification of one test case must likely also be propagated to all clones of this test case. To avoid test duplication, many test management tools fortunately offer reuse mechanics, often called »shared steps« or »calls«. These work akin to method calls in source code. But to use them effectively, you first have to know, which test cases copy others. A clone analysis can reveal this:
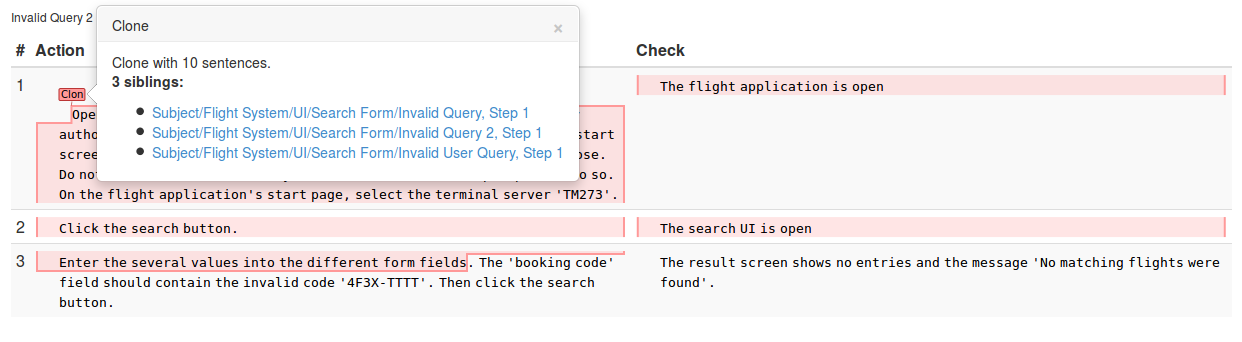
The above image shows a clone (highlighted in red), i.e., the highlighted passage appears in several other test cases as well. The popup shows the other test cases that also contain the same text and provides links to let you jump there. This makes it easy to find good candidates for extracting »shared steps«, e.g., login sequences that have to be performed at the start of every test case or common validation tasks.
Keeping an Overview
At CQSE and HEJF we employ all of these analyses and more in practice on many different test suites. For large test suites, the number of findings quickly becomes overwhelming and needs to be managed properly to achieve effective quality improvement. For this, we offer tools that aggregate metrics, identify hot spots (i.e., test cases with many problems) and give you a graphic overview over the entire test suite. Combined with a process to manage, prioritize and fix these findings, we have found that the »findings flood« can be handled very well.
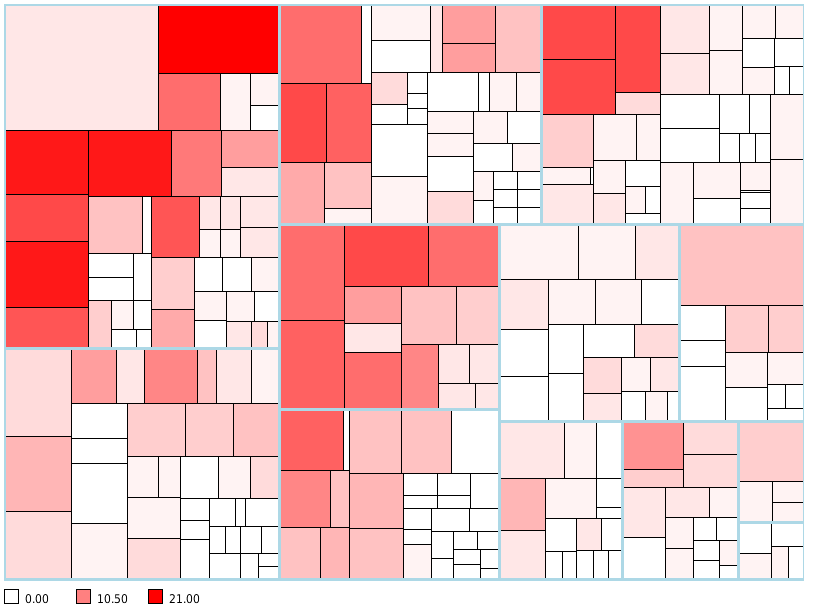
This image shows a tree map, i.e., a graphical representation of all test cases. Each rectangle represents a different test case and its size corresponds to the length of the text in that test case. Test cases that are grouped together in the test management tool (e.g., because they belong to the same feature/requirement/folder) are also grouped together in this map. The darker the red of a rectangle, the more problems were detected in the corresponding test case. Such a visualization makes it easy to find hot spots, i.e., areas where many problems are located.
Comparison with Code Analysis
Static analysis is also a widely used technique in source code quality management. Although the intent is similar, such approaches for natural language text differ in some key aspects. Compared to source code, natural language text does not have such strictly enforced syntax and semantics. Often, test cases are written by non-native speakers and contain domain- or project-specific words and concepts. Spelling and grammar mistakes are abundant. Furthermore, data and test instructions are often kept in the same document, i.e., what the tester has to do and which data should be entered. Finally, there is much less tool support for these types of artifacts. Where there are IDEs with auto-completion and type hierarchies for source code, most test-related tools don’t even offer a spell checker. Nonetheless, static analysis of natural language text is possible and can yield some great insights into the quality of a test suite and pave the way for continuous improvement.

