-
 Blog
Blog
-
Testing Changes in SAP BW Applications
As my colleague Fabian explained a few weeks ago, a combination of change detection and execution logging can substantially increase transparency regarding which recent changes of a software system have actually been covered by the testing process. I will not repeat all the details of the Test Gap Analysis approach here, but instead just summarize the core idea: Untested new or changed code is much more likely to contain bugs than other parts of a software system. Therefore it makes sense to use information about code changes and code execution during testing in order to identify those changed but untested areas.
Several times we heard from customers that they like the idea, but they are not sure about its applicability in their specific project. In the majority of these cases the argument was that the project mainly deals with generated artifacts rather than code, ranging from Python snippets generated from UML-like models and stored in a proprietary database schema to SAP BW applications containing a variety of artifact types beyond ABAP code. Even under these circumstances Test Gap Analysis is a valuable tool and may provide insight into what would otherwise be hidden from the team. In the following I explain how we applied Test Gap Analysis in an SAP BW environment.
The Starting Point
Developers in the BW realm work with lots of different artifacts. There are Transformations, Data Transfer Processes, Queries, Info Cubes, Info Providers, and many more. Most of their properties and interrelations can be modelled using the vendor-provided graphical development environment. In cases where this is not sufficient, custom ABAP code snippets (called Routines) can be attached at well-defined points using a code-editor window. As a consequence, it is very hard to track changes in a BW application. Of course, there is metadata attached to every element containing the relevant information, but seeing all changes that have occurred since a given point in time (e.g., the current production release) is not a trivial task. The same holds for execution information.
Since we were already using Test Gap Analysis for transactional ABAP systems, we reached out to a team developing in BW and showed them some results for their own custom ABAP code.
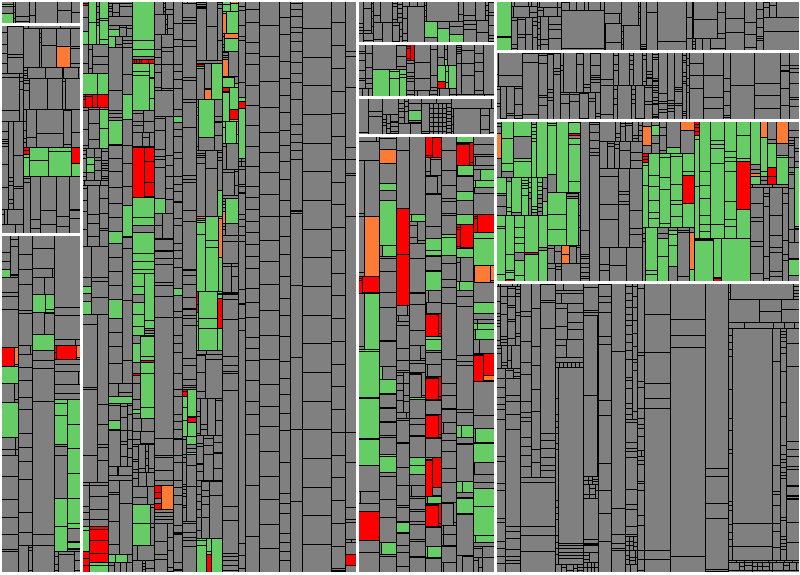
Figure 1: Test Gaps in Manually Maintained ABAP code only
The picture shows all ABAP code manually maintained by the development team. Each rectangle having white borders corresponds to a package, and the smaller rectangles within correspond to processing blocks, i.e., methods, form routines, function modules, or the like. As explained in Fabian’s post, grey means the block was unchanged, while the colors denote changed blocks. Out of these, the green ones have been executed after the most recent change, while the orange ones have untested modifications with regard to the baseline, and the red ones are new and untested.
Moving Forward
As expected, the feedback was that most of the development effort was not represented in the picture, since development mainly happened in Queries, Transformations and DTPs rather than plain ABAP code. The other object types mentioned above are mainly data containers rather than containing functionality. Another insight, however, was that all these artifacts are transformed into executable ABAP code. Therefore, we analyzed the code generated from them, keeping track of the original objects’ names. The result was (of course) much larger.
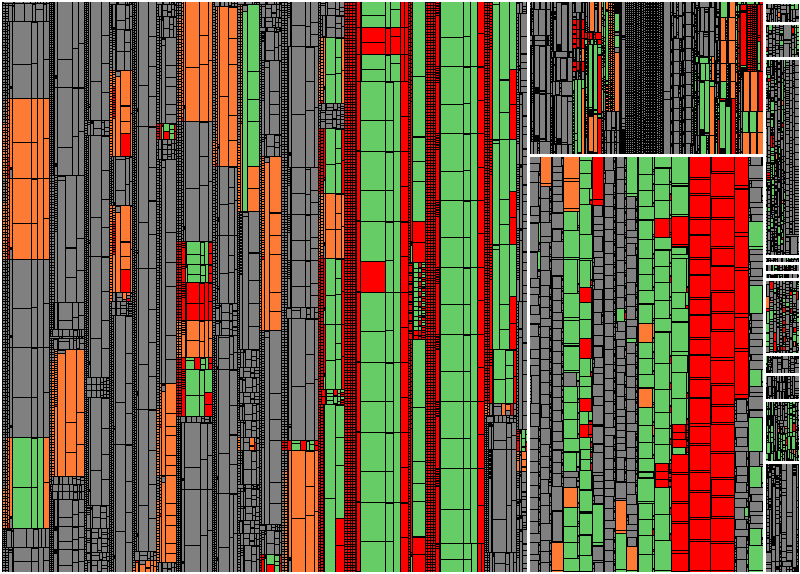
Figure 2: Code generated from DTPs (left), Transformations (middle top), Queries (middle bottom), and manually maintained code (far right)
Including all the programs generated out of BW objects, the whole content of the first picture shrinks down to what you can see in the right column now, meaning that it only makes up a fraction of the analyzed code. Therefore, we have two main observations: First, ABAP programs generated from BW objects tend to get quite large and contain a lot of methods. Second, not every generated method is executed when the respective BW object is executed. In order to make the output more comprehensible, we decided to draw only one rectangle per BW object and mark it as changed (or executed) if at least one of the generated methods has been changed (or executed). This way, the granularity of the result is much closer to what the developer expects. In addition, we shrink the rectangles representing these generated programs by a configurable factor. Since the absolute size of these programs is not comparable to that of manually maintained code anyway, the scaling factor can be adjusted to achieve an easier to navigate visual representation.
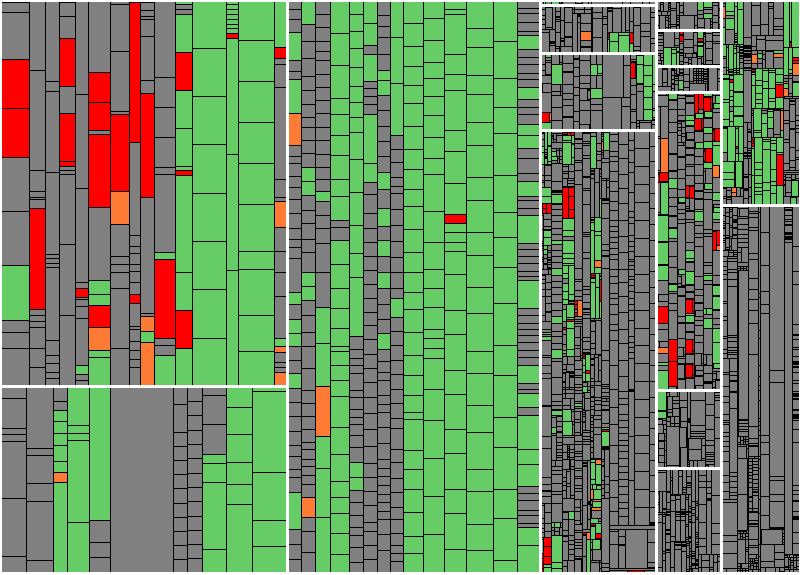
Figure 3: Aggregated and scaled view for generated code (left to middle) and manually maintained code (right)
The Result
With this visualization at hand, the teams can now directly see which parts of the application have changed since the last release in order to focus their test efforts and monitor the test coverage over time. This helps increasing transparency and provides timely feedback regarding the effectiveness of the test suite in terms of change coverage.
What about Other Technologies?
In order to use Test Gap Analysis, just two basic requirements have to be fulfilled:
- The generated code has to be in a source code language that is understood by the ConQAT toolchain. Systems running on the JVM or on Microsoft’s .NET platform are an exception to this rule. For those, the analysis is currently performed on byte code.
- A coverage profiler has to be in place, whose format is understood by Teamscale or ConQAT. This can be SAP’s Coverage Analyzer (SCOV) or Usage Procedure Logging (UPL), Cobertura for Java, our own low-footprint profiler for the .NET platform, or e.g. coverage.py for Python code.
