-
 Blog
Blog
-
The Trouble with JaCoCo: Lessons Learned
When we set up the Test Gap Analysis for one of our customers, we have to instrument their application with a code coverage tool which records the lines of code executed during their tests. This coverage information is an important input for the analysis. For Java, our go-to tool is JaCoCo. It works really well for our use case, is a mature tool with many configuration options and has little performance impact in most scenarios. We have, however, run into several recurring problems with it which can make its use cumbersome.
In this post, I’m going to show you the problems we encountered and present our solution, which makes setting up the Test Gap Analysis for Java applications (and getting code coverage in general) a lot easier.
The Problems
When we set up the analysis, our customers are usually most interested to see the results for their manual tests. Thus, we need to set up JaCoCo in a test environment that is not fully automated, as humans have to interact with it. This means, for example, that the application may be restarted infrequently or not running until a tester starts testing. It also means that we may be getting multiple test sessions on the same machine on any given day, maybe even in parallel. The following is a list of problems we ran into in this scenario:
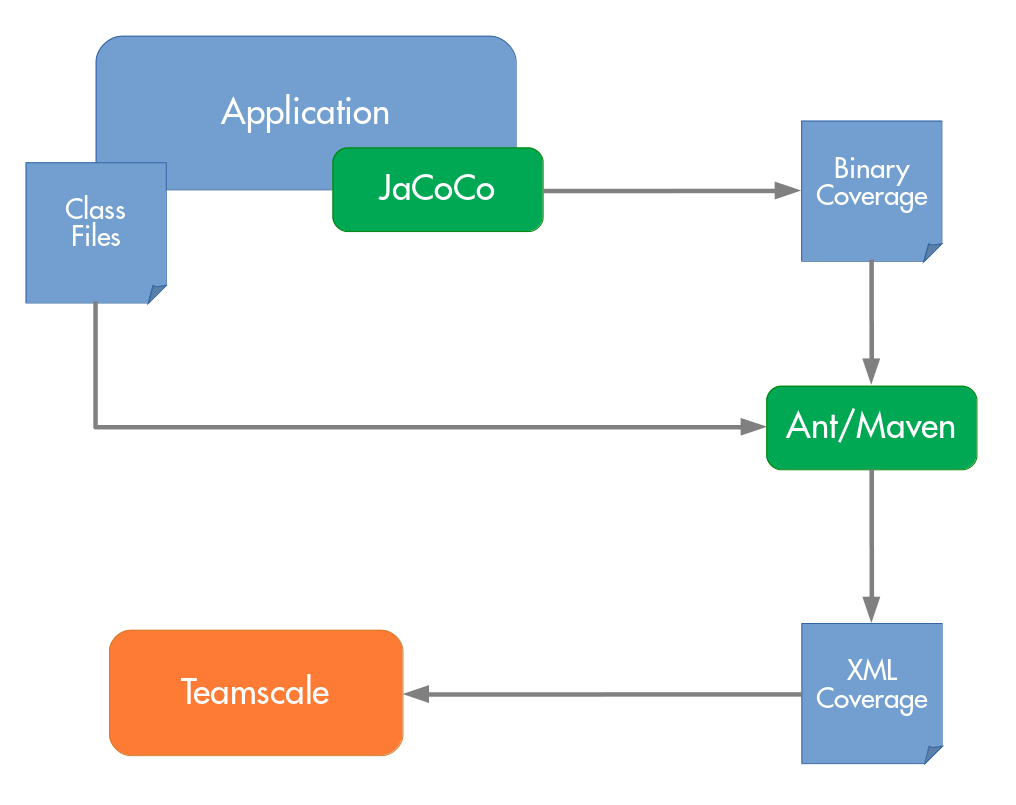
In its default configuration, JaCoCo writes to disk directly. You specify a file name on the command line when registering the Java agent and the resulting coverage is written to the specified file. The problem with this approach is that, unless you work around this issue with wrapper scripts etc., multiple launches of the application will all write to the same file - potentially overwriting or corrupting the result.
JaCoCo only writes the coverage file after the application is shut down (or more accurately, the JVM that contains it). This means that in environments where you don’t want to regularly restart the application—e.g., when it’s running in an application server—you won’t get any results for a long time. Since one of our goals with the TGA is timely feedback on the progress of testing, this is a big headache for us.
Furthermore, if writing the coverage file takes a lot of time, e.g., with huge applications, you may run into timeouts from, e.g., the application server. This may go as far as your application getting killed while it’s still writing the coverage file, resulting in lost coverage information.
Let’s assume that you have a setup that can reliably work around the aforementioned problems, you’ll still have to convert the binary output file that JaCoCo produces to XML. This conversion is pretty cumbersome as it currently has to be done from Maven or ANT and requires that the exact class files of the profiled application are available at conversion time. So you’ll either have to copy those to the server that handles the conversion together with the coverage files—or you’ll have to do the conversion on the test servers, including installing Maven or ANT there. Usually that’s not what our customers prefer.
As you can see, all of these little problems combined lead to quite the complicated setup just to be able to reliably get coverage information from a test server. Here’s the entire picture of the »traditional« JaCoCo setup:
Since we don’t want to spend so much effort every time we set this up at a customer’s, we worked on a solution that mitigates these problems.
Our Solution: a New Tool
Our new approach involves a new tool we call our JaCoCo client which runs alongside your normal Java process and handles all of the above-mentioned aspects:
- getting the binary coverage data from JaCoCo
- converting it to XML
- storing it on disk and writing a log file
Here’s what it looks like now:
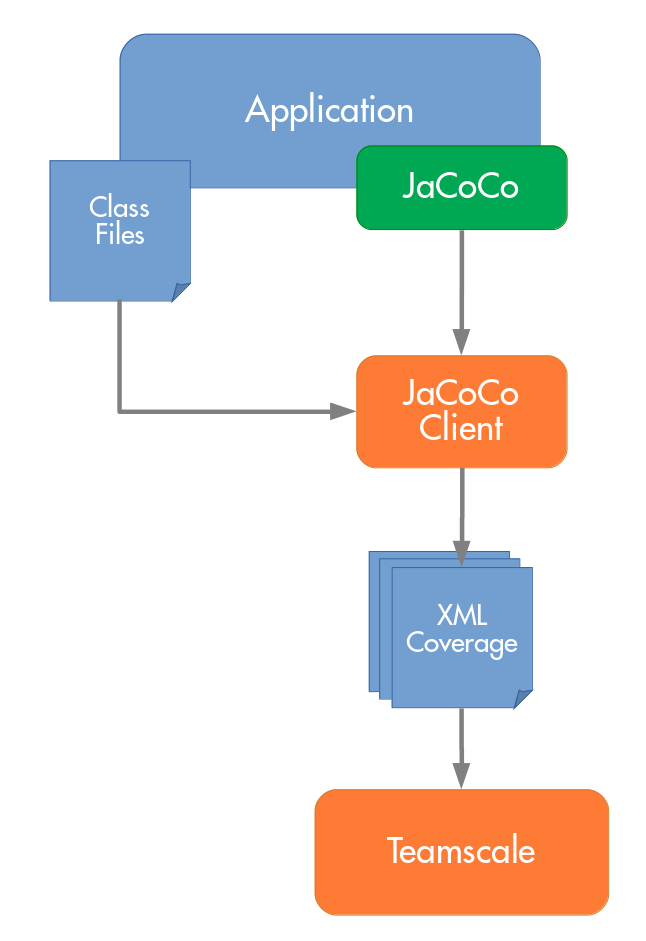
Other than the traditional approach, you’ll have to configure JaCoCo to not write to disk but rather open a TCP port. The JaCoCo client will connect to this port and retrieve the coverage information directly from there at regular intervals.
This means that you can get coverage data whenever you want, without having to restart your application. Since our client takes care of writing the resulting coverage to disk, you’ll also never have to worry about lost coverage due to overwritten files anymore. Finally, since the tool does the conversion to XML at the time the coverage is fetched from JaCoCo, we can guarantee that the correct class files are used in the process.
As starts and stops of the application may happen at any time, we made the JaCoCo client robust against this. Thus, when the client notices that the JaCoCo port is no longer open, it will regularly try to reconnect and simply resume its work once the application is started the next time.
As you can see, this new tool allows us to cut back on a lot of automation tasks that used to be in assorted bash or Powershell scripts and is all around much more robust. Setting up the TGA for your Java application has never been easier!
What’s next?
We have some further ideas for this tool. One obvious improvement will be to have the tool upload the coverage directly to Teamscale instead of just writing it to disk. This obviously doesn’t work in all environments (some of our customers have some very tight security), but it is helpful in case your test servers can talk to the Teamscale server directly.
Another interesting approach that we are currently evaluating in a Master’s thesis is, whether recording coverage on a per-test-case level can help you during your regular testing. We found, for example, that we can reorder your test cases in a way that finds the most bugs by running just a small number of your test cases. This helps you cut the costs of executing your test cases and get feedback faster. Integrating this per-test-case recording of coverage into the tool will help us get these benefits to you.
If you’re currently using the TGA for a Java application and are interested in changing your setup to use our JaCoCo client, contact us and we’ll help you get started!

