-
 Blog
Blog
-
Quality Tasks and Quality Goals
Quality Control is one of the major services we do at CQSE. The aim of quality control is to stay (almost) clean of quality deficits or to achieve a continuous improvement regarding quality. In most cases we focus on the quality of source code.
To keep it simple, I will stick to code quality throughout this post. I will focus on two aspects of this process: Quality tasks and how these relate to quality goals. For more details of the overall quality control process see the earlier blog post from Martin on Improving Software Quality and Does Quality Control Really Make Your Code Better? from Daniela.
Quality Tasks
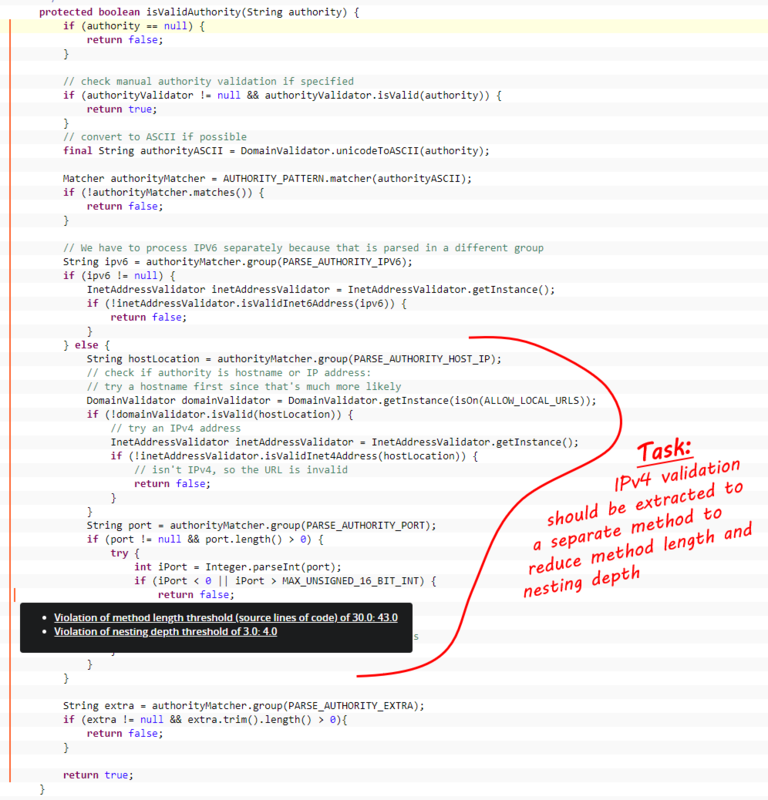
Often, when we are in the role of a quality engineer and apply the quality control process, the most effort goes into the definition of quality tasks. A quality task refers to one or more related quality deficits—typically these are findings from static code analysis. See below an example of two findings which should be addressed in one task (the code snippet is taken from Jenkins open-source project):
However, a task is not just a pointer on a collection of findings to fix, but more important, a task also outlines a suggested solution. Some typical task descriptions are for example:
- »Resolve the redundancy between class c1 and c2, e.g. by introducing an additional base class and move the methods and attributes related with x there.«
- »Shorten the overly long method m, e.g. by extracting the calculation of x to a separate method. Also reduce the deep nesting in this method, e.g. by inverting the if-conditon and immediately return«
- »Reduce the length of file f, e.g. by placing the static methods in a utility class.«
The benefit of such tasks is not only the obvious improvement of the quality when a task is fixed. The major value is probably in its side-effects:
- The development team is becoming more aware to keep an eye on the results of static analysis tools.
- By the actionable suggestion how to fix certain findings, restraints against cleaning up are lowered as the solution is more obvious.
- As the suggested solutions reflect best practices how to write good code, there is also a training effect. Tasks help to spread the knowledge about best practices throughout the development team.
I mentioned already that identifying such tasks is a quite laborious task for the quality engineer. But it is not only the formulation of the tasks, first it is the identification of relevant findings. Of course, we write tasks only for findings, where the fix would actually improve the quality of the code. Thus we filter false-positive and usually we also omit very minor violations. But the main selection criteria is given by the applied quality goal of a project.
Quality Goals for Selecting Tasks
In green-field software development, where you start writing your entire code newly from scratch, it might be possible to address all findings in tasks and fix them. But if you have to deal with a grown code base, where you could even encounter thousands or tens of thousands of existing findings, this approach is not practicable, see also the earlier post from Nils about Don’t Fix All Your Quality Deficits. And even in new developed software, findings accumulate quite fast and you have again to select which of these are worth to fix. That is where quality goals come into play. Typically we either follow a preserving or improving quality goal for defining quality tasks.
- Preserving means that at least the quality should not further decay or in other words: No new findings should be introduced. Hence, all new findings since a certain baseline are addressed in tasks
- Improving means that a continuous gain in quality is targeted. To achieve this, we focus not only on the new findings, but also on findings in modified code. Here, the developers should follow the boy scout rule: »always leave the campground cleaner than you found it.« Hence, new findings and existing findings in modified code since a certain baseline are addressed in quality tasks
With either of these two strategies, the amount of relevant findings is reduced to a manageable subset of all findings. The main advantage of these two goals is that both focus on recent changes in the code, thus the developer who did the change usually can remember that piece of code. Thus there is no big effort to get familiar with the specific code again and the additional risk to introduce bugs by fixing the findings is minimized.
Daniela’s before mentioned blog post shows the effect of this quality control process where the described strategy of defining tasks is an essential part, more details about this case study can be found in the respective ICSME paper where the results were published. (There, the improving goal was followed).
Tool Support
Of course, to efficiently apply such a process, a good tool support is needed. Probably not a big surprise, but Teamscale comes with many features for this. Actually, it was one of the main design decisions when we started to implement Teamscale that it should be perfect for the described quality control process. Before we were mainly using ConQAT and thus we were well aware of the shortcomings of 2nd generation quality tools (see Martin’s post on The Evolution of Software Quality Processes and Tools for more details).
Teamscale allows to manage tasks and the baseline concept enables focusing on new findings and findings in modified code. Teamscale also incorporates heuristics to differentiate between refactorings and actual functional changes, what is essential to follow the boy scout rule. Finally, a key functionality is the reliable tracking of findings: e.g., if code moves around, classes or methods get renamed, etc., than the existing findings at baseline should not be marked as new findings. Only with a reliable findings tracking focusing on new findings will work in practice. The incremental analysis approach, where the code is analyzed from change to change, is the foundation to achieve this.
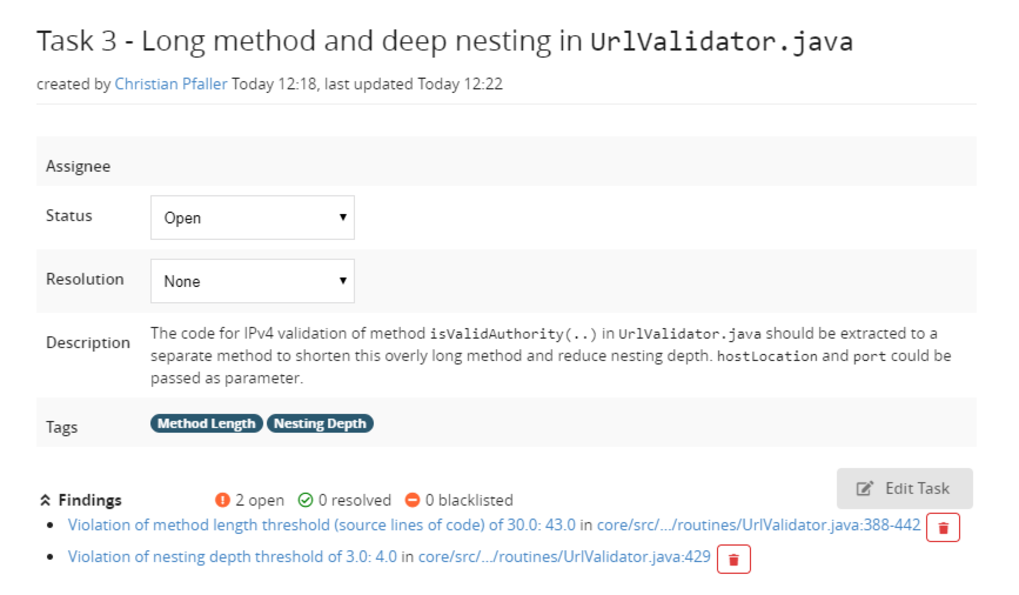
The following screenshot shows how the task from above looks like in Teamscale. You could also view it live on our Teamscale demo instance (requires registration).