-
 Blog
Blog
-
Lessons from Code Reviews: There is no Exhaustive ...
At CQSE we perform peer reviews for almost every line of code that we write to achieve high-end quality control. With the experience we gained (and still gain!) we also help customers to establish review processes or review portions of their code. Besides questions regarding process and tooling there is one question that we get regularly asked: »Is there a list of rules that you apply for reviewing code?« The answer is always »No«—and this is not because we want to keep such knowledge secret. With this blog post I will try to explain why such an exhaustive checklist simply does not exist.
Why we perform code reviews
First of all, let’s understand why we at CQSE perform code reviews.
The initial development of our quality analysis tool ConQAT started in 2005 and since then more than 60 people contributed to it (CQSE employees, staff from TU München, students). Our successor product Teamscale uses ConQAT as its core technology. Thus our main goal was and is to keep the code maintainable, as we want to understand and alter it even years after it has been written.
Hereby, manual code reviews help us to:
- try to catch bugs before they creep into production code
- identify code that is hard to read or bad structured—we’re not satisfied if the code just works, it must be maintainable
- ensure the coding style is consistent—actually, one cannot tell which of our code has been written by whom
- transfer knowledge between contributors—there is no exclusive code ownership of any file; it must have been touched by at least two persons
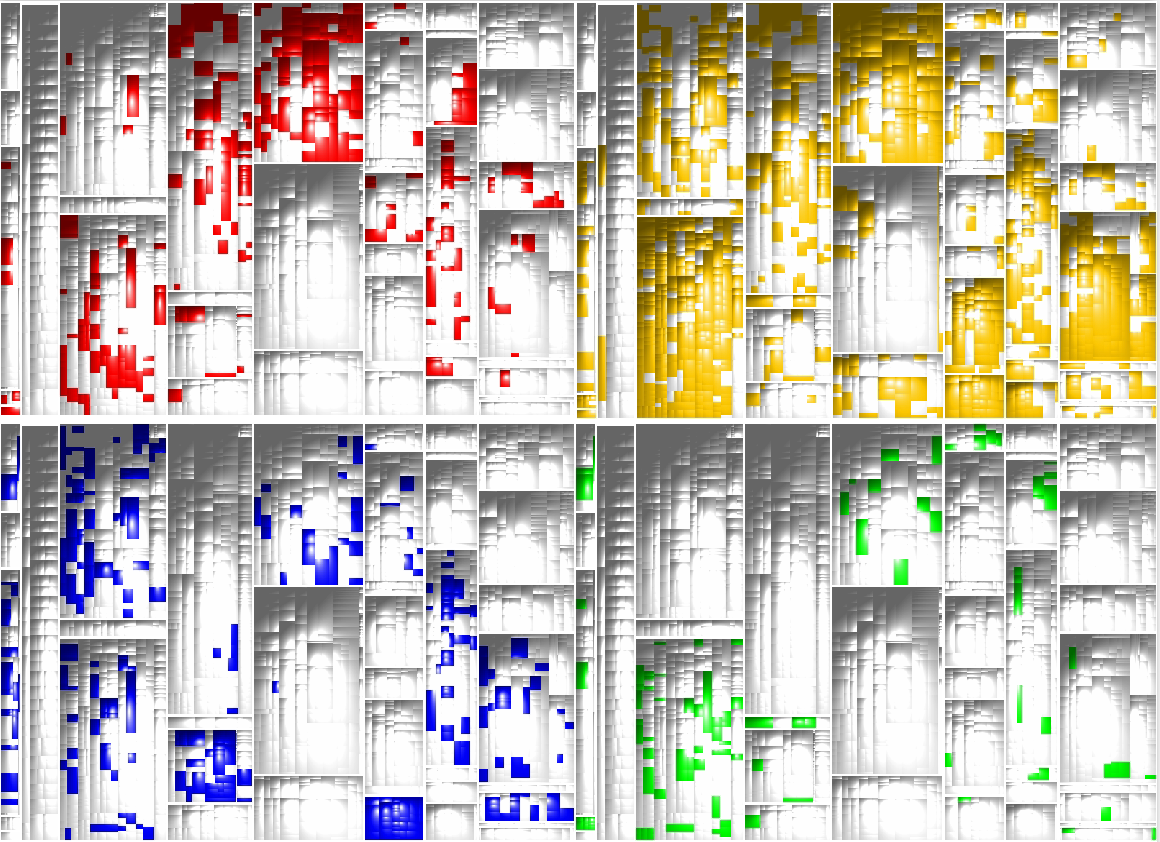
The latter aspect is the most important when it comes to teaching new contributors and it is visualized in the following figure. It shows four treemaps of the ConQAT source code with each treemap corresponding to a single contributor. A colored rectangle marks a file that has been touched by the contributor. If you look closely, we all worked in different areas, but there is hardly a file that has been touched solely by one person.
The subjectiveness of reviews
As already outlined by my colleague Benjamin we are performing reviews in a file-based fashion. A file may enter review if it is clean of issues that can be found by static analysis tools (you don’t want to review a Word document if someone did not run the spell checker, right?) and the review concludes after all manually identified issues are resolved. This brings me back to our initial question, what are these manual findings? Actually it’s a mixture of everything mentioned in the previous section: Suggestions to simplify the control flow, reminding of some corner cases, some nit-picky coding style criticism, … this list may go on forever.
When introducing code reviews in customer development teams, we are usually starting the kick-off workshop with a short code example the attendees have to review. After everyone is done we collect the list of all findings on a flip chart. With this little exercise we want to show is the following:
- No one finds all of the findings
- In each workshop new findings are discovered
So there is no golden solution for the implemented problem nor for the findings of the code review. In the end the review findings are based on your own coding experience and personal preference. Of course the personal preference has to align with overall project guidelines, but coding is sometimes like arts—one prefers straight lines, the other prefers playful arrangements.
Due to this subjectiveness of reviews, one simply cannot gather and publish an »exhaustive checklist« for manual code reviews that one can follow step by step.
OK, there is no exhaustive checklist—but what should I look for?
Basically using your own rationale:
- would I have implemented some parts different?
- which regions of the code are hard to understand?
And again, this boils down to personal experience. The more background you have in a given domain and programming language the notion of readability and your review findings will change. For deeper insights Kasper B. Graversen wrote an interesting article on the changing notion of code readability lately. In this article he outlines with a catchy example the evolution of a simple method from a novice programmer to a veteran coder.
You might ask now, »If we have to use our experience, how can novice contributors achive this?« The answer is simply, let them code and let them perform code reviews!
We saw that no one can find all possible problems in the code, so even if the amount of review findings from a novice contributor is not as high, they will learn from reading your code: They accommodate with the coding style, application architecture and code reviews itself. As code reviews usually criticize the work you have spent a substantial amount of time on, it is important to understand code reviews not as personal critique but as suggestion to improve the code. Hence, new contributors of our code usually start with a code review even before they receive the first review. We want them to give critique before receiving critique on their own work.
Besides reviewing the code of colleagues, novice programmers will also learn from examples of code that is hard to read or follows bad practice. These examples have to be bundled with suggestions on how to improve the code. During the development (and review) of our own code analysis software we saw several reoccurring anti-patterns that may be improved in terms of clean code. But such a (non-exhaustive and highly subjective!) collection of anti-patterns is a topic of its own and may be published in a sequel to this post…
