-
 Blog
Blog
-
Why is Java's String#replace() so slow?
One of the services we offer is called Test-Gap Analysis (TGA). It helps you identify changes in your code that have not been covered by your tests since the last release. I have been working on TGA for the last few months and never had to worry about performance problems. Analyzing a code base of over 30,000 classes took about 15 minutes, which is what you’d expect for a complex analysis.
Last week, though, we tried executing it on a new project (> 60,000 classes) and after the analysis had run for 2 hours with no end in sight, we had to face the facts: we had a performance problem. The following graph shows our code’s approximate performace:
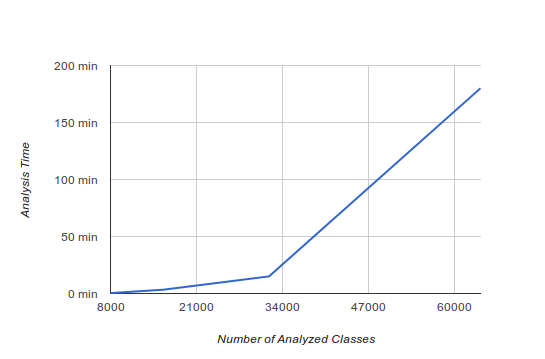
I took a quick look at our code and after a few minutes I thought I had a pretty good idea of what the problem might be. Just to confirm, I ran our analysis with a profiler attached. As expected, my first guess was... way off!
The analysis showed that the JVM spent an extrodinarily large portion of its time inside Java’s String#replace(). Investigating further, I identified this piece of code as the culprit:
protected void applyAllTypeRenames() {
for (Method method : processedMethods) {
String body = method.getBody();
for (Entry<String, String> entry : typeRenames.entrySet()) {
body = body.replace(entry.getKey(), entry.getValue());
}
processTransformedBody(method, body);
}
}Here, we apply a list of replacements to a string. For each method that must be processed and for each entry in the map, we call String#replace() once. What you cannot see here is that in the problematic case, the outer loop had several tens of thousands of iterations, and the map contained more than 10,000 entries at the worst of times. This makes for a LOT of iterations.
Are regular expressions faster?
So the question was: how can we make this faster? Our first idea was to use regular expressions. Instead of iterating over the map and performing one replacement at a time. We created one gigantic regular expression that matched all the keys in the map, applied it to the string and replaced each match after looking up the replacement in the map. The time it takes java.util.regex.Pattern to compile such a huge regular expression: around 6 seconds. The time we save when using this approach: none. It seems like regular expressions are just a bad choice when you’re trying to perform a lot of literal replacements.
Thus, we were back to literal string replacements. To get an idea of how the Java standard library does this and to find a way to optimize that code for our particular situation, we took a look at String#replace(). Guess how it is implemented:
public String replace(CharSequence target, CharSequence replacement) {
return Pattern.compile(target.toString, Pattern.LITERAL)
.matcher(this)
.replaceAll(Matcher.quoteReplacement(replacement.toString());
}That’s right: with regular expressions! So it's little wonder that our first try wasn't faster than the built-in method.
Our performance fix for String # replace()
After we saw this, we decided to create our own utility method that would do literal replacements on a StringBuilder, saving us the trouble of creating millions of temporary String and Pattern objects. This is what we came up with:
/**
* Replaces all occurrences of keys of the given map in the given string
* with the associated value in that map.
*
* This method is semantically the same as calling
* {@link String#replace(CharSequence, CharSequence)} for each of the
* entries in the map, but may be significantly faster for many replacements
* performed on a short string, since
* {@link String#replace(CharSequence, CharSequence)} uses regular
* expressions internally and results in many String object allocations when
* applied iteratively.
*
* The order in which replacements are applied depends on the order of the
* map's entry set.
*/
public static String replaceFromMap(String string,
Map<String, String> replacements) {
StringBuilder sb = newStringBuilder(string);
for (Entry<String, String> entry : replacements.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
int start = sb.indexOf(key, 0);
while (start > -1) {
int end = start + key.length();
int nextSearchStart = start + value.length();
sb.replace(start, end, value);
start = sb.indexOf(key, nextSearchStart);
}
}
return sb.toString();
}This change alone brought the analysis time down from »I think I’m aborting this, it’s been running for over two hours« to a little over 15 minutes. Together with some other improvements, the analysis now completes in less than 4 minutes!
Of course, this does not have to be the end. As my colleague Benjamin Hummel pointed out: we could apply all these replacements in linear time with the Aho-Corasick algorithm. It remains to be seen if our current optimizations are enough or if even larger projects will provide new challenges for us in the future.
